聚类分类—算法以及python实现
🧠 使用 Python 实现高效凝聚层次聚类(Agglomerative Clustering)
在本篇博客中,我们将一起探索如何使用 Python 实现一个高效的 凝聚层次聚类(Agglomerative Hierarchical Clustering)算法,并支持三种不同的簇间距离度量方式:single linkage, complete linkage 和 average linkage。我们还将通过可视化展示不同方法的效果,并分析其优劣。
📚 一、什么是凝聚层次聚类?
凝聚层次聚类是一种 自底向上的无监督聚类算法,它的核心思想是:
每个数据点初始时都是一个独立的簇,然后逐步合并最相似的两个簇,直到达到预设的簇数。
与 K-Means 不同,它不需要提前指定簇的数量即可构建整个聚类树(dendrogram),因此非常适合探索性数据分析。
⚙️ 二、代码概述
🔍 功能亮点:
- 支持三种 linkage 方法:
'single': 最短距离法(最近邻)'complete': 最长距离法(最远邻)'average': 平均距离法
- 使用 最小堆(heapq) 加速查找最近簇对
- 对 Iris 数据集进行特征选择后聚类
- 绘制原始标签与不同 linkage 聚类结果对比图
📦 三、依赖库介绍
1 | import numpy as np |
| 库 | 用途 |
|---|---|
numpy |
高效数组操作 |
pandas |
数据读取与处理 |
matplotlib |
可视化绘图 |
heapq |
最小堆实现优先队列 |
scipy.spatial.distance |
计算成对距离 |
📐 四、核心函数详解
1. 簇间距离计算函数
1 | def cluster_distance(c1, c2, dist_matrix, method='single'): |
- 功能:根据指定的
linkage方法计算两个簇之间的距离。 - 使用场景:
'single': 用于识别链状分布的数据。'complete': 更关注簇内紧密性。'average': 两者折中,适合大多数情况 。
2. 初始化距离矩阵
1 | dist_matrix = squareform(pdist(features[:, feature_indices])) |
pdist:计算所有样本两两之间的欧氏距离。squareform:将压缩的距离向量转换为 N×N 的距离矩阵 。
3. 初始化每个样本为独立簇
1 | init_clusters = [[i] for i in range(numberOfsamples)] |
- 初始时每个样本是一个簇,用索引表示。
4. 构建最小堆维护簇对距离
1 | for i in range(len(clusters)): |
- 使用
heapq构建最小堆,每次取出当前最近的簇对进行合并。 - 时间复杂度从 O(N³) 降低至 O(N² log N) 。
5. 合并簇并更新堆
1 | while sum(valid) > numberOfcluster: |
- 有效簇标记:使用
valid数组记录哪些簇是有效的。 - 动态更新距离:合并后重新计算新簇与其他簇的距离并插入堆中。
📊 六、可视化展示
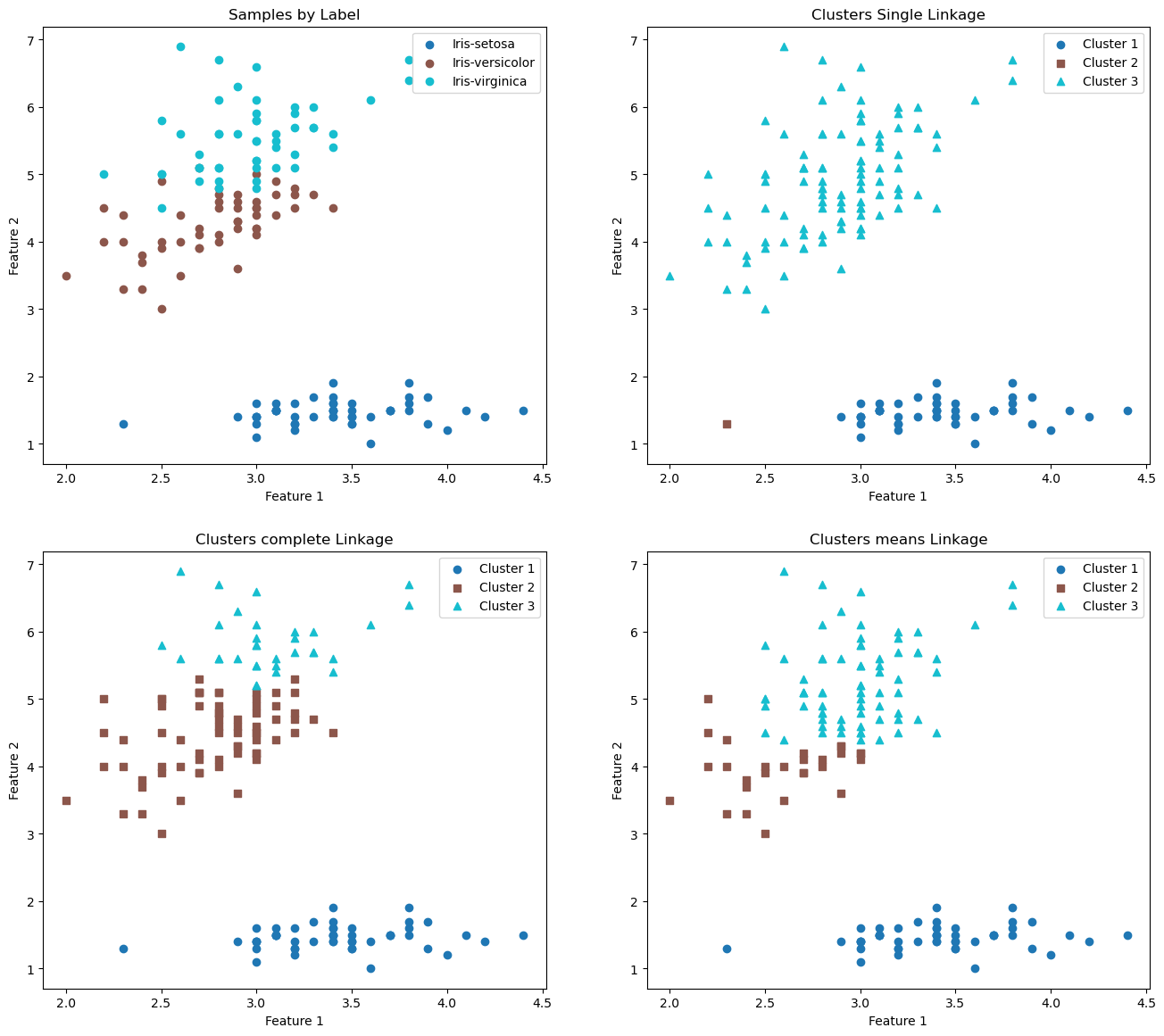
我们绘制了四种图像:
- 原始数据按真实标签显示
'single'linkage 聚类结果'complete'linkage 聚类结果'average'linkage 聚类结果
每种方法都使用不同颜色和形状的标记来区分簇。
示例代码片段:
1 | plt.scatter( |
🧩 七、三种 Linkage 方法对比
| Linkage 方法 | 特点 | 适用场景 |
|---|---|---|
'single' |
容易形成“链式”簇 | 适用于流形型数据 |
'complete' |
强调簇内紧凑性 | 适用于球形分布数据 |
'average' |
折中方案,平衡表现 | 通用性强 |
📚 参考资料
- [1] Scipy pdist & squareform 文档
- [2] NumPy 与 Pandas 简介
- [3] 密度峰值聚类算法综述
- [4] 自适应密度峰值聚类算法
- [5] 层次聚类与 DPC 算法对比
🧠 使用 Python 实现向量化 K-Means 聚类算法
K-Means 是一种经典的无监督聚类算法,广泛应用于数据挖掘、图像压缩、客户分群等领域。本文将带你一步步理解并实现一个高效的向量化 K-Means 算法,并通过 sklearn 加载 Iris 数据集进行实战演示。
📦 一、环境依赖与数据准备
我们使用如下库:
1 | import matplotlib.pyplot as plt |
✅ 数据加载
1 | iris = datasets.load_iris() |
X: 特征矩阵(150 × 4)numberOfcluster: 类别数为 3
⚙️ 二、使用 sklearn 的 KMeans 进行聚类
我们先调用 sklearn.cluster.KMeans 快速完成聚类任务:
1 | estimator = KMeans(n_clusters=numberOfcluster) |
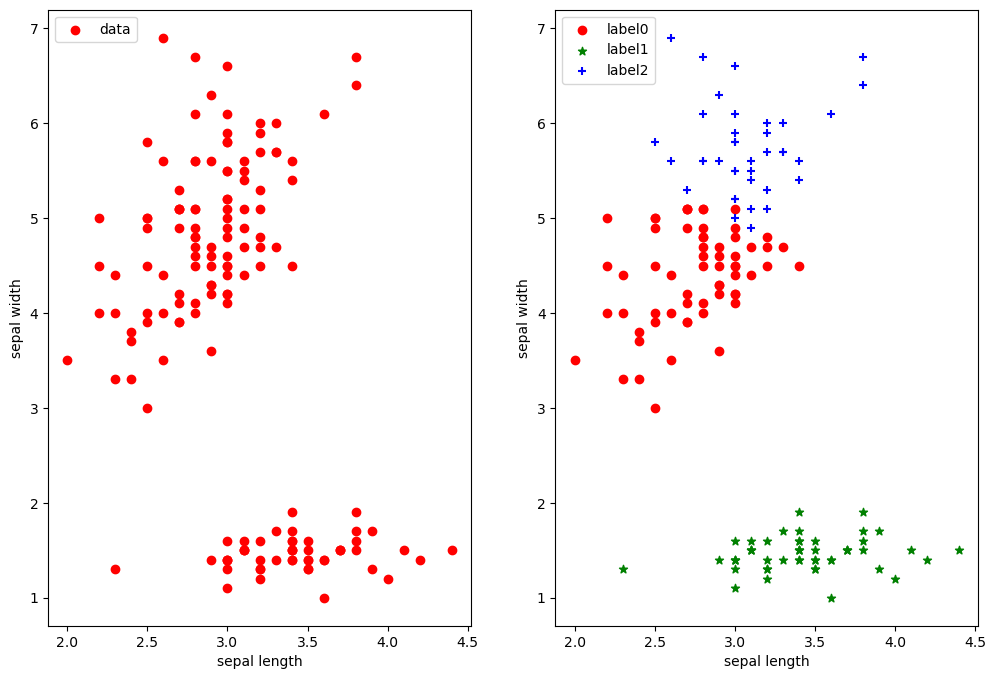
然后绘制原始数据和聚类后的结果图:
1 | plt.figure(figsize=(12, 8)) |
✅ 使用 sklearn 可以快速完成聚类,但了解其内部实现更有助于深入理解算法原理 。
🧩 三、手动实现向量化 K-Means
为了更深入理解 K-Means 的工作原理,我们实现了向量化版本的 K-Means 算法,避免了传统的嵌套循环,提高了计算效率。
1. 向量化计算距离矩阵
1 | def compute_distances(dataSet, centroids): |
- 利用 NumPy 广播机制一次性计算所有点到质心的距离。
- 避免双重 for 循环,提升性能 。
2. 分配样本到最近质心
1 | def assign_clusters(distances): |
- 沿列方向取最小值索引,确定每个样本所属簇。
3. 随机初始化质心
1 | def randomCenter(dataSet, k): |
- 从数据集中随机选择
k个样本作为初始质心 。
4. 更新质心
1 | def update_centroids(dataSet, cluster_indices, k): |
- 对每个簇计算均值作为新质心。
5. 主函数:向量化 K-Means
1 | def KMeans_vectorized(dataSet, k, max_iter=100): |
- 收敛条件:新旧质心几乎相等时停止迭代。
- 最终返回质心、簇标签和迭代次数。
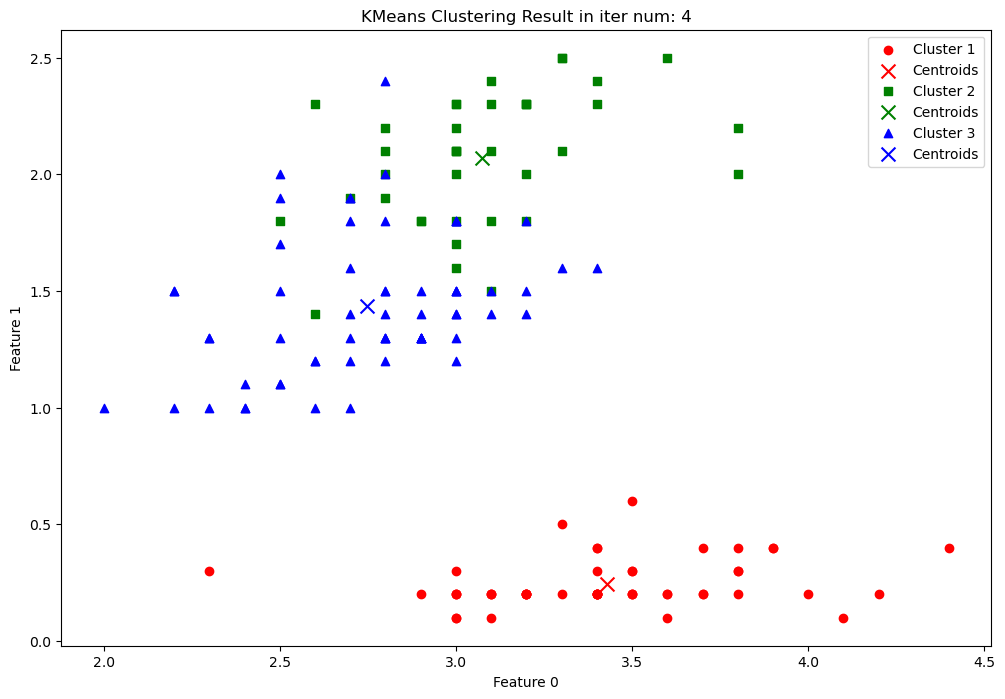
📊 四、可视化聚类结果
1 | plt.figure(figsize=(12, 8)) |
- 不同颜色代表不同簇。
- 不同标记区分簇内点与质心。
📌 五、总结
| 功能 | 描述 |
|---|---|
| 向量化实现 | 提升聚类速度,适用于大规模数据 |
| 随机初始化 | 简单易懂,但可能陷入局部最优 |
| 收敛判断 | 使用 np.allclose() 避免无限迭代 |
| 可视化支持 | 帮助直观理解聚类效果 |
📚 六、参考资料
- [1] Scikit-learn 官方文档:KMeans 聚类介绍
- [2] KMeans 初始化方法详解:
k-means++vsrandom - [3] NumPy 和 Matplotlib 在机器学习中的应用
- [4] 向量化计算提高效率的方法
🧠 使用 Python 实现自定义 DBSCAN 聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够发现任意形状的簇,并且能识别出噪声点。本篇博客将带你一步步实现一个高效的 自定义 DBSCAN 算法,并使用极坐标方式生成测试样本数据集进行验证。
📦 一、环境依赖与数据准备
我们使用如下库:
1 | import numpy as np |
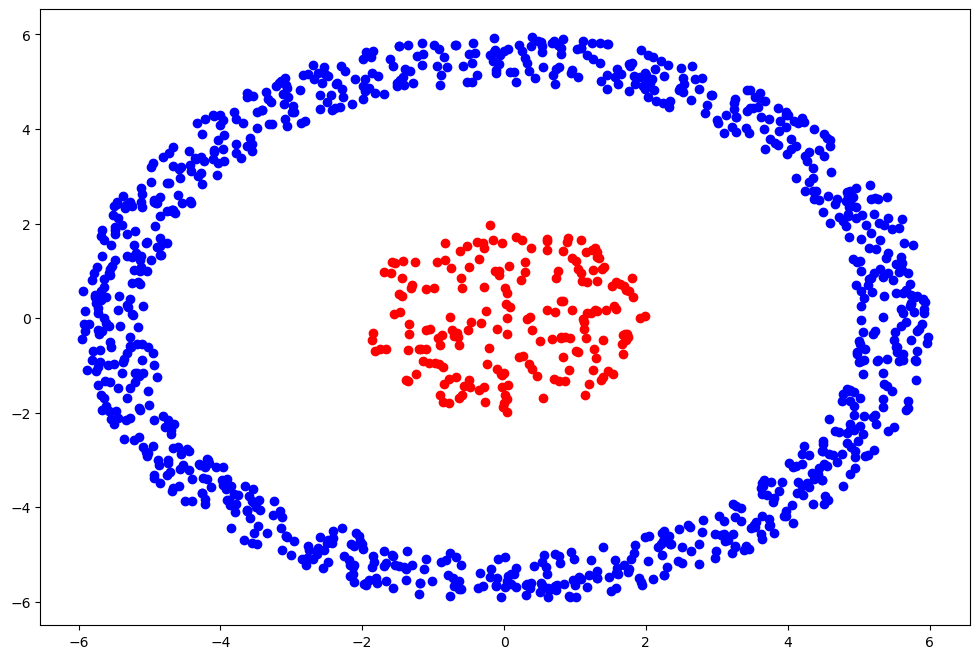
✅ 生成测试样本
我们通过极坐标生成两个不同半径范围内的样本点,模拟环形分布的数据:
1 | def generate_sample(): |
✅ 该方法参考了随机采样策略,适用于测试和可视化分析。
⚙️ 二、DBSCAN 类设计与实现
1. 初始化参数
1 | class DBSCAN: |
| 参数 | 说明 |
|---|---|
eps |
邻域半径,用于判断邻近点 |
value\_threshold |
密度峰值选择阈值 |
2. 计算距离与密度
1 | distances = cdist(X, X, metric='euclidean') |
- 使用
cdist一次性计算所有点之间的欧氏距离 - 每个点的局部密度是其邻域内点的数量
3. 计算最小距离
1 | min_distances = [] |
- 对每个点,找到比它密度高的点,并计算到这些点的最小距离
4. 选取聚类中心
1 | density_times_min_distance = density * np.array(min_distances) |
- 通过
density × min\_distance排序,结合阈值筛选聚类中心
5. 广度优先扩展聚类
1 | Have_labeled = [] |
- 使用 BFS 扩展簇,将邻域点标记为相同标签
6. 统一标签编号
1 | final_labels = np.unique(self.labels) |
- 将原始索引标签映射为连续整数,便于后续处理
📊 三、可视化聚类结果
1 | unique_labels = np.unique(labels) |
- 不同颜色代表不同簇
-1表示噪声点
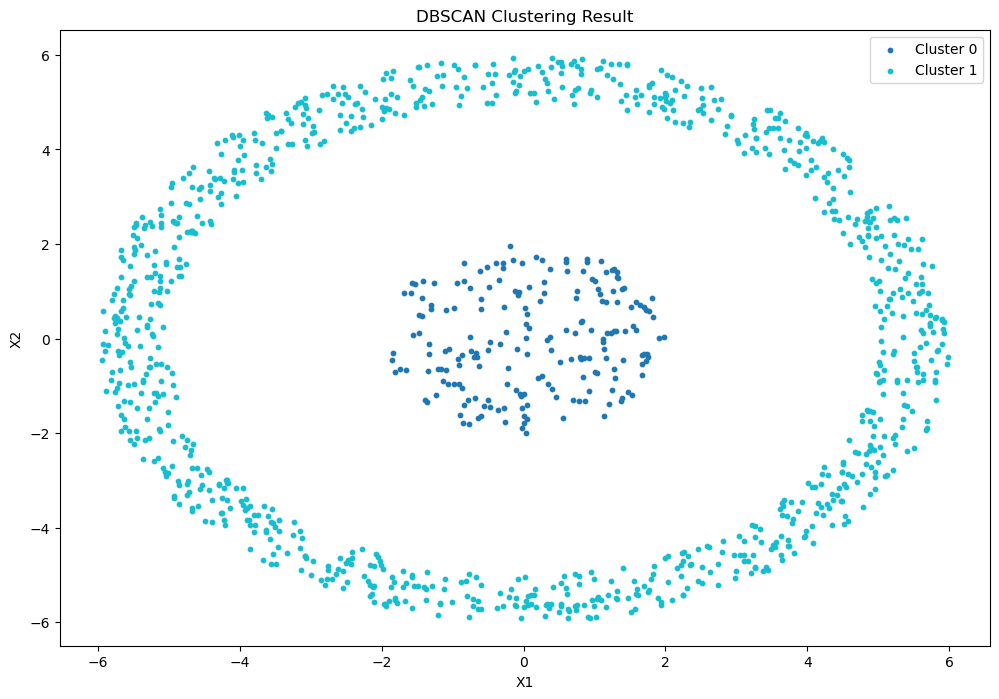
📌 四、总结与优化建议
| 功能 | 描述 |
|---|---|
| 极坐标生成样本 | 更适合环形或球形数据集 |
| 向量化操作 | 提升性能,避免双重循环 |
| 支持噪声识别 | 是 DBSCAN 的核心优势之一 |
| 可视化清晰 | 帮助理解聚类效果 |
✅ 优化建议:
- 使用
K-D Tree或Ball Tree加速邻域查询 - 替换固定阈值为动态选择策略
- 支持自动确定
eps和min\_samples - 使用
numba或Cython加速核心循环部分
📚 五、参考资料
- [1]
scipy.spatial.distance.cdist用法 - [2] 测试样本生成方法
- [3] 聚类算法在机器学习中的应用
- [4] DBSCAN 算法原理详解
🎉 感**谢阅读,希望这篇博客对你理解和实现 DBSCAN 聚类有所帮助!
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Katarina's diary!
相关推荐

2025-09-18
Adapose——跨环境的人体关键点识别
AdaPose —— Yunjiao Zhou文献综述《AdaPose: Towards Cross-Site Device-Free Human Pose Estimation with Commodity WiFi》独特的创新思想: 不同域之间的差异如何泛化或者说对齐? 本篇论文不按照传统方式在特征空间分布上进行对齐,而是**提出从”映射规则”**上进行统一! 文章将整个模型分为三层:输入域中采集的CSI、中间层的特征空间、输出估计关键点的坐标,其中的映射规则包括将CSI信息映射成一个特征、将CSI信息映射成姿态关键点的坐标。 本文认可不同的域(源域、目标域)是存在本质差别的,文中通过 $D_{input}$、$D_{feature}$ 以及 $D_{output}$ 分别表示不同域最原始的差异(数据)、特征提取后的分布差异(缩放)、姿态估计的分布差异,且这些差异是必然存在的。 传统方式:特征空间分布对齐,是通过调整 $D_{feature}$,将不同域采集的具有 $D_{input}$ 差异的CSI映射到相同的特征空间分布上 $D_{feature} = 0$; ...
2025-09-20
Unsupervised adversarial domain adaptation——对抗生成跨域泛化
Unsupervised Adversarial Domain Adaptation —— Han Zou文献综述《Robust WiFi-enabled Device-free Gesture Recognition via Unsupervised Adversarial Domain Adaptation》研究目的 (Research Objective) 本研究旨在解决现有WiFi手势识别系统在实际部署中的核心痛点:环境动态性导致的模型失效问题。当系统部署到新环境(如从会议室移到办公室)时,无需重新收集标注数据和训练新模型,即可保持高识别准确率。 本文的创新点: 数据创新:利用CSI相位差作为输入 摒弃了传统方法中易受噪声影响的CSI幅度,转而使用接收端天线对之间的CSI相位差来构建数据帧。 相位差能有效消除由硬件(如载波频率偏移CFO、采样频率偏移SFO)引入的固定相位偏移,从而提取出更能反映人体动作的”干净”信号,对微小手势更敏感。 多场景下的如何实现模型泛化: 已知一个正常运行的模型分为三层,CSI原始数据、特征提取和分类器输出姿态。本文认为不同域下相同的姿...

2025-09-19
MultiFormer——基于迭代的高准确率姿态估计
MultiFormer —— Wenhui Xiong研究目的:将在一个场景训练的姿势识别模型扩展到不同的场景中; 可能的方法(建模上): 将不同的场景抽象为一个样本,多个场景训练(小样本学习); 将时间、频率、空间特征抽象为张量,添加场景布局的影响; 根据协议提出的标准室内WiFi建模,抽象为token AI学习算法提高训练的模型对未知环境的适应能力,增强泛化能力 Keypoints: Cross-Scene Adaptive environment dynamic environment robustness Ada boost Meta-Learning Data Augmentation for Generalization 对于当前研究的问题: 初始数据检索与清理:CSI是否会影响估计,环境中的信道很多,直射信道是否会影响反射或散射信道?仅考虑了CSI幅值用于姿态估计,忽略相位导致识别效果下降? 将CSI提取出feature,通过PAPM得到PAM和PCM,但是都是2维空间域中的识别,忽略了深度,如果多目标的姿态有重叠,是否影响估计的效果? 使用图像信息作...

2025-09-19
Densepose——基于UV坐标的高精度姿态估计
DensePose From WIFI —— Jiaqi Gen文献综述:《DensePose From WiFi》目的:论文旨在解决传统人体姿态估计方法面临的三大核心问题: 环境限制:RGB 相机在光照不佳或存在遮挡时性能会急剧下降; 成本与功耗:LiDAR 和雷达等传感器价格昂贵且功耗高,难以在家庭等日常场景普及; 隐私问题:在浴室、卧室等私密空间部署摄像头会引发严重的隐私担忧。论文的最终目的是开发一种低成本、易于部署、保护隐私且对光照和遮挡鲁棒的新型人体感知技术,为智能家居、健康监护等应用铺平道路。 遇到的困难: CSI是一维数据,与空间域的信息没有相关性,不像图片,每一个像素点都是是空间域的一个映射; 前人没有相关研究,都是基于TOF、AOA的中心定位; 研究方法:大致流程如下:首先采集信号的CSI,对CSI的幅值和相位进行预处理,包括采样、插值以及数据矫正。之后通过一个双支编码器,将幅值和相位vector编码为2D的feature maps,对应图像姿态识别中的原始图像(这里做了一个域转换:从WIFI信号域 → Feature Maps特征域; 1D...
2025-09-21
面向WiFi-Sensing的文献总结
文献综述

2025-05-29
SVM——Python代码实现以及解析
支持向量机(SVM)原理详解与代码解析一、SVM算法原理详解1. 核心思想支持向量机通过最大化分类间隔实现最优分类,其数学本质是求解一个凸二次优化问题。核心思想包括: 最大间隔原则:寻找使类别间距离最大的分类超平面 支持向量:决定分类边界的关键样本点 核技巧:通过核函数将低维不可分数据映射到高维空间 2. 数学基础(1) 线性可分情况$$\min_{w,b} \frac{1}{2}||w||^2 \quad \text{s.t.} \quad y_i(w^T x_i + b) \geq 1$$ $ w $:超平面法向量 $ b $:偏置项 $ y_i \in {-1,1} $:类别标签 (2) 非线性情况(使用核函数)$$K(x_i,x_j) = \phi(x_i)^T\phi(x_j)$$ 常用核函数: 线性核:$ K(x,y) = x^Ty $ 多项式核:$ K(x,y) = (x^Ty + c)^d $ RBF核:$ K(x,y) = e^{-\gamma ||x-y||^2} $ (3) 正则化参数C$$\min_{w,...
