CIFAR-10数据集介绍
CIFAR10包含有一共60000张32x32的彩色图像,这些图片中一共有10类不同的事物,每一类有6000张样本。这些图片按照5:1的比例随机分为训练集以及测试集。

下面将在这个开源的数据集上实现图像的分类,目前计划通过ResNet-18模型实现上述的分类功能;
Python代码实现以及详解
导入必要的库以及依赖
我们这里使用Pytorch框架实现模型的训练以及结果的预测;
1
2
3
4
5
6
| import torch
import torch.nn as nn
from tqdm import tqdm
from torchvision import transforms
import torchvision
from torch.utils.data import DataLoader
|
导入 tdqm 库将训练的过程可视化,该库能够将训练的进度以进度条的形式显示出来;由于我们要实现的是图片的识别分类功能,这里选择导入 torchvision 库并使用预训练的模型参数提高训练的正确率以及速度;
数据预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
batch_size = 32
train_set = torchvision.datasets.CIFAR10(root='./CIFAR', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
val_dataset = torchvision.datasets.CIFAR10(root='./CIFAR', train=False, download=True, transform=transform)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
|
首先我们先定义了一个图片变换结构,作用是将图片,向量矩阵转换为Pytorch中定义的一个全新的数据结构——张量(Tensor);之后根据该数据集的标准差对所有张量标准化归一化;
之后定义了训练集数据以及验证集数据的加载器,能够设置一定的 batch\_size 每一次取数据进行训练或者验证的时候取一整个 batch ,提高训练的速度;同时还能够设置是否随机选择样本,以及线程数量;
1
2
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
|
定义设备,如果当前支持CUDA则使用CUDA作为训练的设备,否则为CPU;CUDA的训练速度要比CPU的训练速度快,而且训练的效果会更好一些;
1
2
3
4
5
| net = torchvision.models.resnet18(pretrained=True)
num_ftrs = net.fc.in_features
net.fc = nn.Linear(num_ftrs, 10)
net = net.to(device)
|
这里我们使用 ResNet-18 模型进行训练以及识别,为了加快训练的速度以及提高训练的准确率,选择导入Pytorch中预训练的模型参数;由于该数据集中只有10个类别,网络只需要10个输出,因此我们单独对网络的最后一层进行修改,将全连接层的输出修改为10;最后将模型导入到设备在。
注意:CUDA与CPU不互通,模型以及数据到需要在同一个设备中;
Net的结构如下:
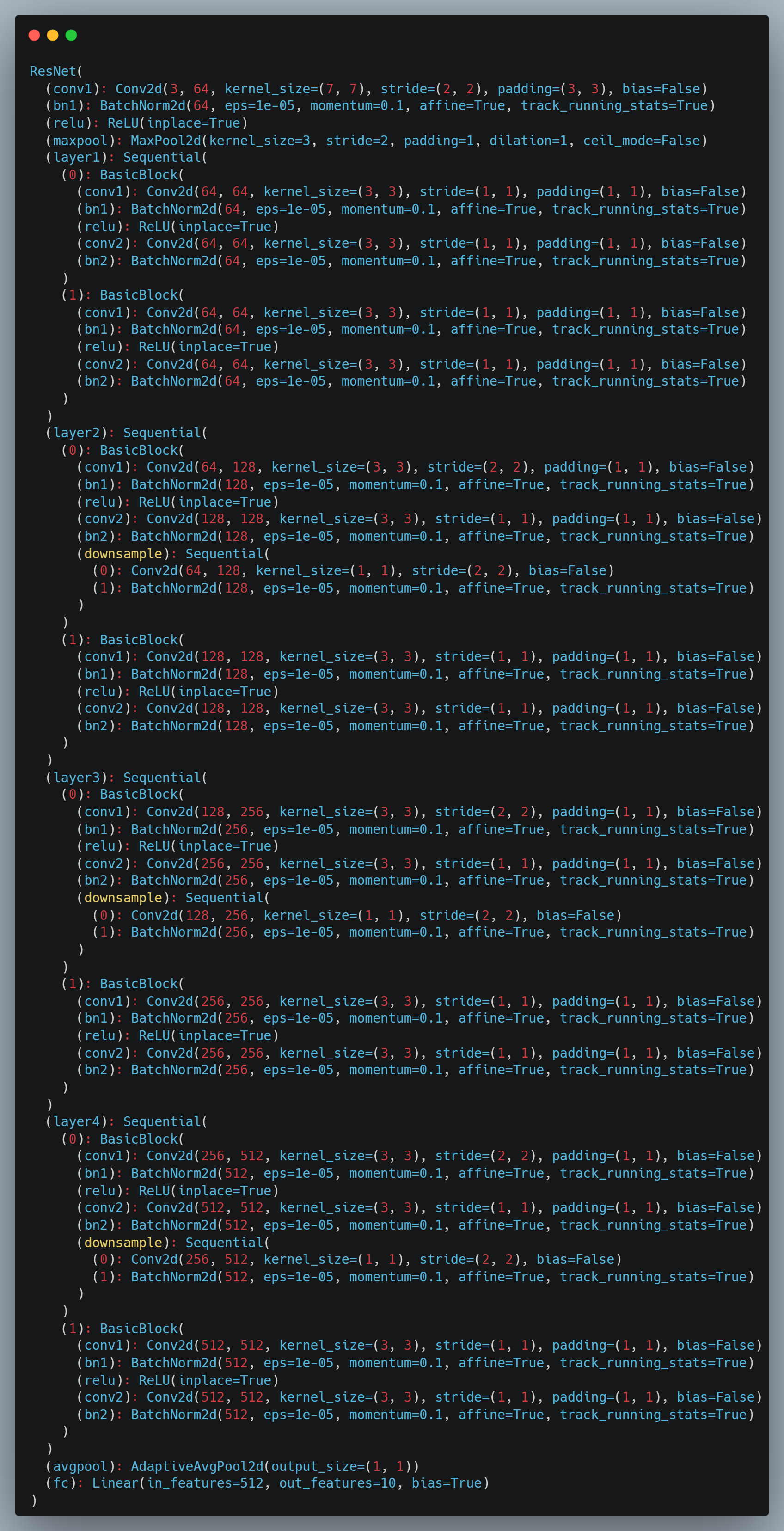
1
2
3
| criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(lr=0.0001, params=net.parameters())
epochs = 10
|
定义比较常见的两个函数作为赏罚函数,损失函数为交叉损失,优化函数定义为AdamW函数,想详细了解可以去参考一下文章:
[1711.05101] Decoupled Weight Decay Regularization
训练轮数为10轮,训练轮数的选取比较有讲究,如果训练次数过少则模型的性能没有到最优;如果训练次数过多,则又会导致过拟合,训练效果下降。因此通常选择一个适中的次数,或者对每次训练的准确率进行判断,发现如果准确率的优化减缓时,意味着当前模型接近收敛,便提前结束训练并保存模型参数;
下面是训练代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| for epoch in range(epochs):
print(f'--------------------Epoch: {epoch}--------------------\n')
net.train()
running_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = correct_train / total_train
print('训练损失:{:.4f},训练准确率:{:.4f}%'.format(train_loss, train_acc * 100))
net.eval()
correct_val = 0
total_val = 0
val_loss = 0.0
with torch.no_grad():
for inputs, labels in tqdm(val_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_acc = correct_val / total_val
print('验证损失:{:.4f},验证准确率:{:.4f}%'.format(val_loss, val_acc * 100))
|
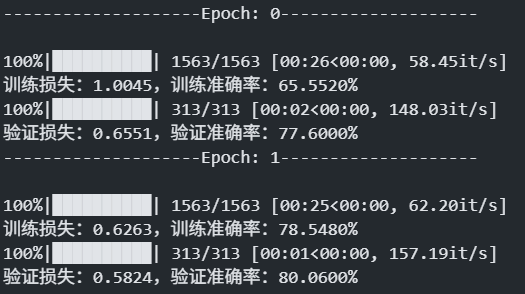
以上就是输出的结果。
在CIFAR-100上实现图像的识别分类
CIFAR-100,同CIFAR-10一样,不同的是该数据集包含有100种不同的实物,要对100个样本类别进行区分,对应的数据量也水涨船高;
理论上两者的模型都差不多,但是ResNet-18对100个任务的区分效率低、效果差,因此我们这里尝试使用MobileNet_v2模型对CIFAR-100数据集进行训练,在损失函数以及优化函数的配置上略有不同:
1
2
3
4
5
6
7
8
9
10
11
12
|
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW([
{'params': model.features.parameters(), 'lr': 1e-4},
{'params': model.classifier.parameters(), 'lr': 1e-3}
])
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=2)
epochs = 20
|
损失函数仍然使用交叉损失函数,但是我们在不同的阶段使用不同的学习率,在特征提取阶段使用小的学习率,分类时使用大的学习率。分类的损失直接与模型的表现有关,因此较高的学习率可以更快的收敛;
使用**分层学习率(layer-wise learning rate decay)**的策略,它的好处包括:
- 保留预训练特征:较小的学习率用于
features,可保持预训练模型学到的通用特征。
- 快速适应新任务:较大的学习率用于
classifier,有利于快速适应 CIFAR-100 新任务。
- 训练更稳定、收敛更快:尤其在轻量网络中,更能体现训练灵活性。
下面是训练代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| best_val_acc = 0.0
for epoch in range(epochs):
print(f'\nEpoch {epoch+1}/{epochs}')
print('-' * 30)
model.train()
running_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in tqdm(train_loader, desc='Training'):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = correct_train / total_train
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc*100:.2f}%')
model.eval()
val_loss = 0.0
correct_val = 0
total_val = 0
with torch.no_grad():
for inputs, labels in tqdm(val_loader, desc='Validation'):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
val_loss = val_loss / len(val_loader)
val_acc = correct_val / total_val
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc*100:.2f}%')
scheduler.step(val_loss)
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), 'best_mobilenetv2_cifar100.pth')
print(f'Best validation accuracy: {best_val_acc*100:.2f}%')
|
输出如下:
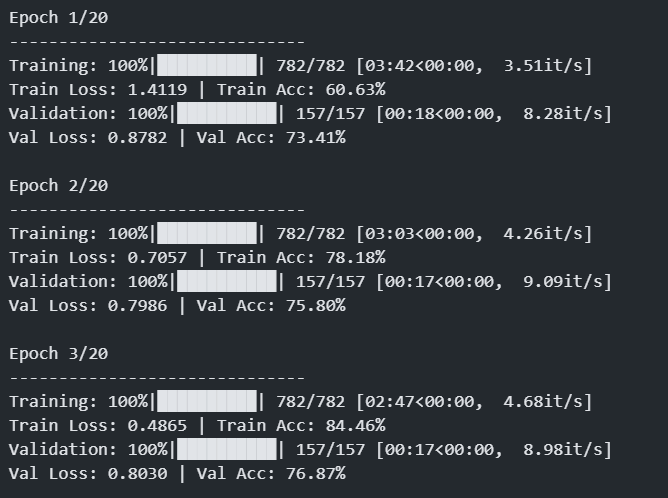
✅ MobileNetV2 相对于 ResNet-18 的优势与适用场景
| 方面 |
ResNet-18 |
MobileNetV2 |
对比与解释 |
| 模型大小 |
约 44.6M 参数 |
约 3.5M 参数 |
MobileNetV2 轻量很多,适合部署在资源受限设备(如嵌入式、手机端)。 |
| 计算效率 |
中等 |
更快(低 FLOPs) |
MobileNetV2 使用 深度可分离卷积,大大降低计算复杂度。 |
| 推理速度 |
中 |
更快 |
推理延迟更低,尤其在 CPU 或边缘设备上。 |
| 准确率(ImageNet) |
Top-1: ~69.8% |
Top-1: ~71.8% |
MobileNetV2 有更优的参数效率。微调后在 CIFAR-100 上表现差距不大。 |
| 结构深度 |
ResNet 残差结构 |
Inverted Residual + Linear Bottleneck |
MobileNetV2 更现代、结构紧凑,有利于特征传递与训练。 |
| 训练稳定性 |
非常稳定 |
稍敏感于学习率、调度器 |
MobileNetV2 结构浅,过大学习率容易震荡,但你设置了合理的 lr 和 scheduler,可以很好控制。 |




