MultiFormer——基于迭代的高准确率姿态估计
MultiFormer —— Wenhui Xiong
研究目的:将在一个场景训练的姿势识别模型扩展到不同的场景中;
可能的方法(建模上):
- 将不同的场景抽象为一个样本,多个场景训练(小样本学习);
- 将时间、频率、空间特征抽象为张量,添加场景布局的影响;
- 根据协议提出的标准室内WiFi建模,抽象为token
- AI学习算法提高训练的模型对未知环境的适应能力,增强泛化能力
Keypoints:
- Cross-Scene
- Adaptive environment
- dynamic environment
- robustness
- Ada boost
- Meta-Learning
- Data Augmentation for Generalization
对于当前研究的问题:
- 初始数据检索与清理:CSI是否会影响估计,环境中的信道很多,直射信道是否会影响反射或散射信道?仅考虑了CSI幅值用于姿态估计,忽略相位导致识别效果下降?
- 将CSI提取出feature,通过PAPM得到PAM和PCM,但是都是2维空间域中的识别,忽略了深度,如果多目标的姿态有重叠,是否影响估计的效果?
- 使用图像信息作为teacher模型的输入进行监督学习,除了图像中的关键点信息外,其余的环境信息是否影响了CSI模型的训练,导致跨场景表现下降?同理,图像作为2D信息缺少深度,是否是限制模型多目标识别的性能?
论文实现:
整体流程介绍:
环境中存在一个发送机和一个接收机,发送机只有单根天线、接收机有多根天线,在收发机中间有单人或多人摆出不同的姿势,做不同的行为。
接收端通过估计CSI,并通过上采样(插值+滤波)的方式将CSI的数据形状修正为模型输入的形状。CSI包含的信息有数据包index、子载波index和信道数量(发射天线x接收天线)。CSI的时间信息关乎一个持续性的行为、频率信息关乎瞬时的姿态,因此上采样操作分别从时域和频域上进行,获得两个Token —— Time Token, Frequency Token且两者彼此独立:
- Time Token:表征一个持续性的动作;
- Frequency Token:表征一个时刻的瞬时姿态;
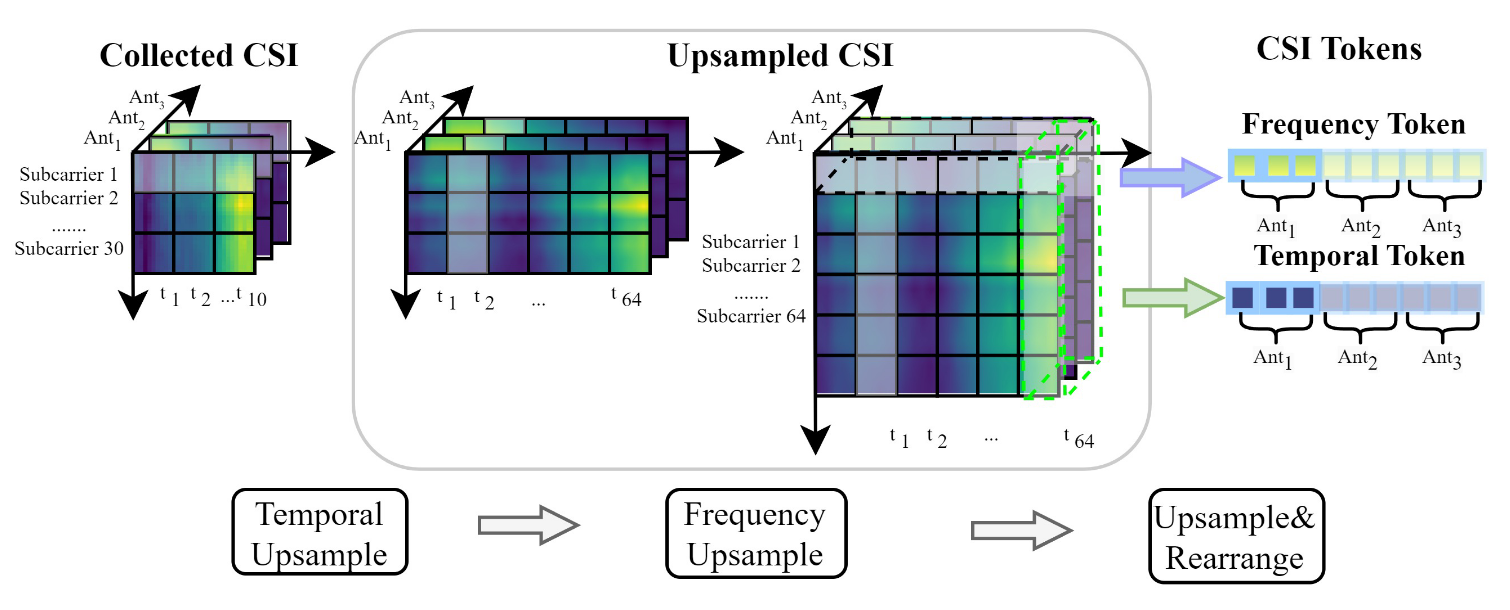
首先将提取出的Token(64个)做正则化,防止数据异化影响注意力分布。Multi-Head Attention模型的输出通过softmax提高关键点的注意力显著性。之后经过一个前向反馈网络(FFN)通过残差连接保障记忆力,最后输出一个1D的通过Multi-Head Attention得到的时、频feature,在输出部分reconstruct成map的形式即可映射到2D的姿态估计中。

feature maps输入Heatmep Decoder中可以解码出PCM(多少个关节多少张PCM,每一张对应一个关节,越亮的pixel表示该处是对应关节的置信度越高)、PAM(多少个关节连接关系多少张PAM,图中每一个点表示该点可能对应的连接方式的矢量,即连接方向和可信度。
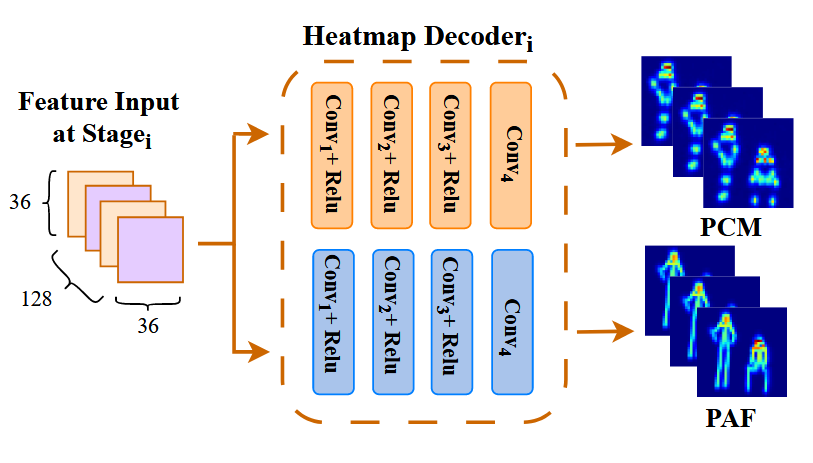
为了提高准确度,参考残差的方式添加了PAPM融合特征机制:
首先初始化参数,将原始CSI提取出的特征通过Heatmap Decoder得到初代PCM、PAM,通过Teacher图像识别的监督结果,反向传播调整参数;
将初代估计结果通过Channel Attention和Spatial Attention得到时-频特征的注意力分布、估计结果PCM中关键点注意力分布,并将得到的注意力分布反馈到CSI提取的feature maps中,调整maps的权重、每一个map中不同点的权重;
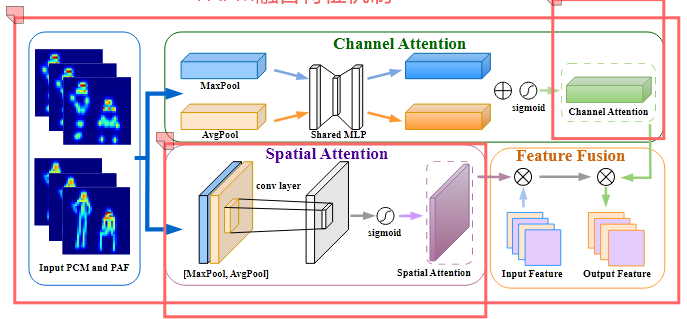
Channel Attention从128个特征图中选择对姿态估计最重要的特征,分配注意力,将加权后的融入下一阶段的姿态估计,提高准确率(容易过拟合)
Spatial Attention通过卷积获得空间的关键点特征,即关节点的位置和连接关系
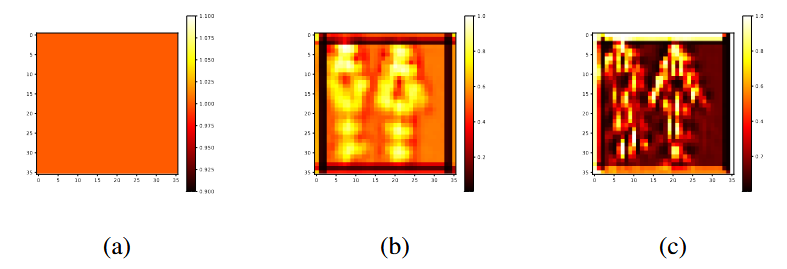
将得到的特征分布、姿态热力分布加权到原始CSI得到训练强化的CSI,此时的CSI对识别结果更加敏感,重新进行姿态估计,重复上述。
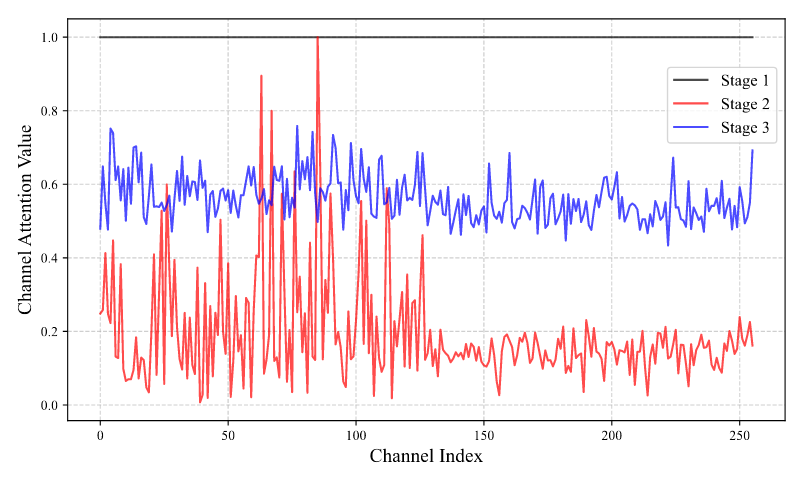
上面两个分别是初始值为1时的Spatial Attention经过三次stage迭代后得到的关节识别注意力热力分布,以及Channel Attention经过三次stage迭代后对不同的特征图(index)注意力权重分布。




