Unsupervised adversarial domain adaptation——对抗生成跨域泛化
Unsupervised Adversarial Domain Adaptation —— Han Zou
文献综述《Robust WiFi-enabled Device-free Gesture Recognition via Unsupervised Adversarial Domain Adaptation》
研究目的 (Research Objective)
本研究旨在解决现有WiFi手势识别系统在实际部署中的核心痛点:环境动态性导致的模型失效问题。当系统部署到新环境(如从会议室移到办公室)时,无需重新收集标注数据和训练新模型,即可保持高识别准确率。
本文的创新点:
数据创新:利用CSI相位差作为输入
- 摒弃了传统方法中易受噪声影响的CSI幅度,转而使用接收端天线对之间的CSI相位差来构建数据帧。
- 相位差能有效消除由硬件(如载波频率偏移CFO、采样频率偏移SFO)引入的固定相位偏移,从而提取出更能反映人体动作的”干净”信号,对微小手势更敏感。
多场景下的如何实现模型泛化:
- 已知一个正常运行的模型分为三层,CSI原始数据、特征提取和分类器输出姿态。本文认为不同域下相同的姿态理论上对于CSI应该相同,但是由于域的差异引入了域标签(domain label)的影响使得不同场景下在特征空间的分布不同。
- 因此作者认为只要能够消除这个domain label的影响,使得在不同场景采集的CSI映射到特征空间仍有相同的分布,于是只需要一个分类器便可以实现不同场景的泛化。
整体流程介绍:
首先在一个确定的环境中进行训练,我们称这个环境为源域(Source domain)。训练的流程大致如下:
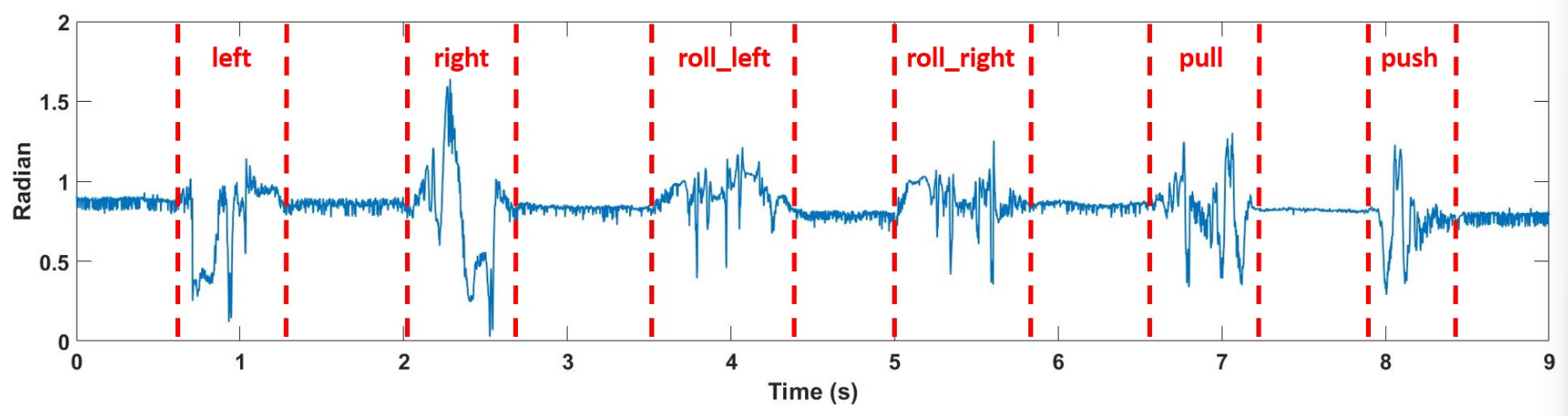
采集源域中的CSI,根据做出的手势对CSI进行标签,得到带标签的CSI样本(CSI是一个时间序列,使用不同接收天线的相位差作为训练样本),CSI对应的信号子载波数量为114(文中使用),不同的动作在同一对接收天线的相同子载波上得到的相位差显著不同;
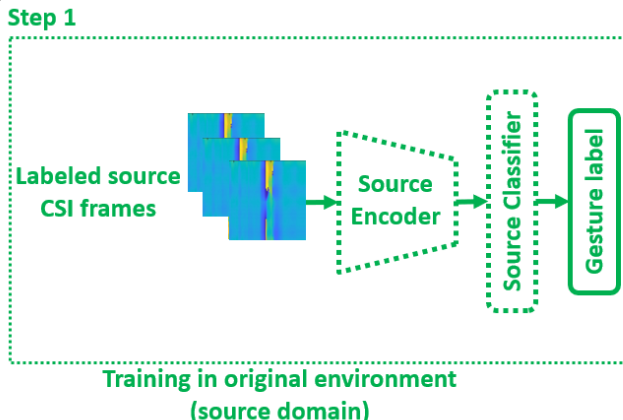
得到用于训练的样本后,首先训练映射模型,将源域中对应CSI得到的样本映射到一个潜在的特征空间,该模型称为 $M_s$,不同的姿态映射到特征空间中符合某种特征分布;之后根据标签,计算损失函数,反向梯度下降优化模型参数,使源域中任意姿态对应的CSI通过该模型都可以正确分类,该分类模型称为 $C_s$,用于将CSI分类为不同的姿态;
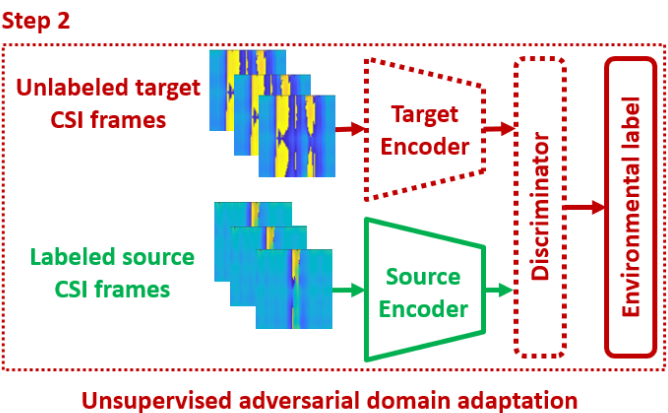
在源域中能够姿态识别后,下一步就是进行场景的泛化,实现步骤如下:
采集目标域中没有标签的姿态对应CSI,使用源域中的 $M_s$ 的参数作为初始参数,训练目标域的映射模型 $M_t$,该映射的目标是使相同姿态的CSI映射到特征空间中保持与相似的特征分布。我们可以假设相同的姿态理论上对应的CSI应该是相同的,但是由于域的不同,导致得到的CSI不同,这种由于域不同导致CSI的差异称作域标签(domain label)!
通过引入一个域判别器(Domain Discriminator) 来实现对抗训练:判别器试图区分数据是来自源域还是目标域,而目标编码器则努力”欺骗”判别器,使其无法区分。这个过程迫使两个域的数据在特征空间中对齐,从而实现”域不变”(domain-invariant)的特征表示。
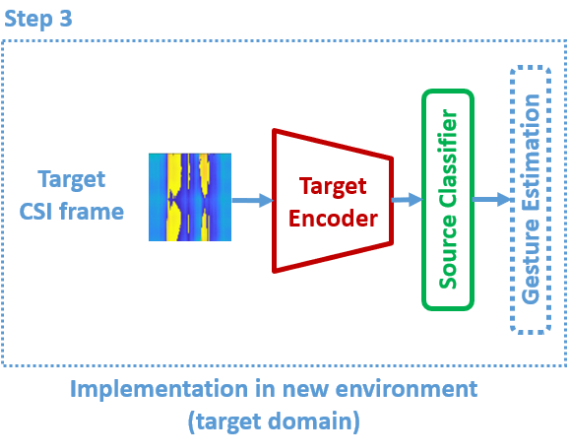
最终实现在任意场景部署都可以实现姿态识别!目标场景中没有训练过的CSI + GAN训练后的特征空间映射模型 $M_t$ + 源域训练的分类器 $C_s$ = 最终预测的姿态。
研究实现 (Research Implementation & Results)
系统实现:
- 使用两台TP-LINK N750路由器(一台TX,一台RX)搭建原型系统。
- 在路由器上刷入自研的OpenWrt固件,实现在5GHz频段、40MHz带宽下采集114个子载波的CSI数据。
- 后端计算单元(笔记本电脑)使用Python进行实时数据处理和模型推理。
实验验证:
- 在两个真实室内环境(会议室和办公室)中进行测试,由2名志愿者执行6种常见手势(左移/右移、左滚/右滚、推/拉)。
- 在原始环境:WiADG的平均识别准确率高达98%,显著优于基线方法WiG和WiAG(分别高出约9-11%)。
- 在新环境(无自适应):直接迁移源模型,准确率骤降至约50%,证明了环境动态性的严重影响。
- 在新环境(有自适应):启用无监督对抗域自适应后,识别准确率大幅提升至66.6% - 83.3%,平均提升超过25%,且无需任何新环境的标注数据。




