Adapose——跨环境的人体关键点识别
AdaPose —— Yunjiao Zhou
文献综述《AdaPose: Towards Cross-Site Device-Free Human Pose Estimation with Commodity WiFi》
独特的创新思想:
- 不同域之间的差异如何泛化或者说对齐?
- 本篇论文不按照传统方式在特征空间分布上进行对齐,而是**提出从”映射规则”**上进行统一!
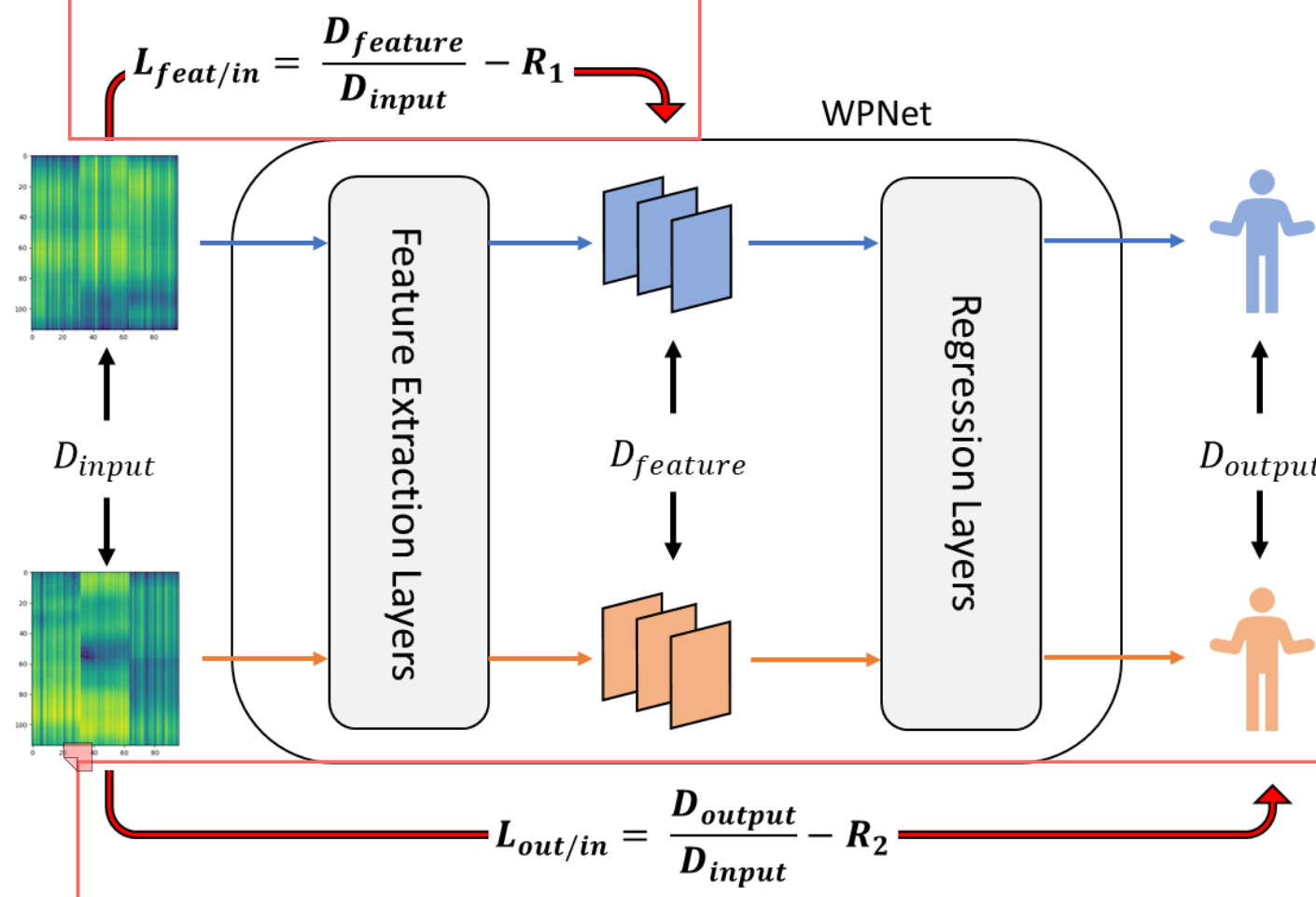
- 文章将整个模型分为三层:输入域中采集的CSI、中间层的特征空间、输出估计关键点的坐标,其中的映射规则包括将CSI信息映射成一个特征、将CSI信息映射成姿态关键点的坐标。
- 本文认可不同的域(源域、目标域)是存在本质差别的,文中通过 $D_{input}$、$D_{feature}$ 以及 $D_{output}$ 分别表示不同域最原始的差异(数据)、特征提取后的分布差异(缩放)、姿态估计的分布差异,且这些差异是必然存在的。
- 传统方式:特征空间分布对齐,是通过调整 $D_{feature}$,将不同域采集的具有 $D_{input}$ 差异的CSI映射到相同的特征空间分布上 $D_{feature} = 0$;
- 本文方式:由于强行修改特征空间的分布对于回归任务(坐标的估计)是不可取的(导致坐标的偏移、缩放),因此定义两个比率 $R_{feat/in} = \frac{D_{feature}}{D_{input}}$ 和 $R_{out/in} = \frac{D_{output}}{D_{input}}$。可以理解为这个比率将不同域的差异(domain label)考虑了,但是又由于输入、特征、输出都有这个差异存在,因此不同域计算的比率是要相同的。
核心问题与挑战
论文明确指出了当前WiFi姿态估计在跨域应用中面临的两大核心挑战:
任务本身的复杂性:姿态估计是一个细粒度的回归问题,需要从信息量有限且粗糙的CSI数据(相比图像的RGB三通道)中,精确预测出17个人体关节点的2D坐标。这要求模型必须能从CSI中提取出微妙而具有代表性的特征,而CSI数据本身在捕捉细微关节运动方面存在固有局限。
环境干扰的主导性:在CSI数据中,由环境变化引起的干扰信号往往比由人体运动引起的有用信号强得多。这导致模型在进行领域自适应时,容易错误地去对齐环境噪声,而非真正的人体动态信息。现有的领域自适应方法大多在特征层面进行对齐,这对于分类任务有效,但对于回归任务却可能导致特征尺度(scale)的错位,从而破坏回归的准确性。
整体的实现流程:
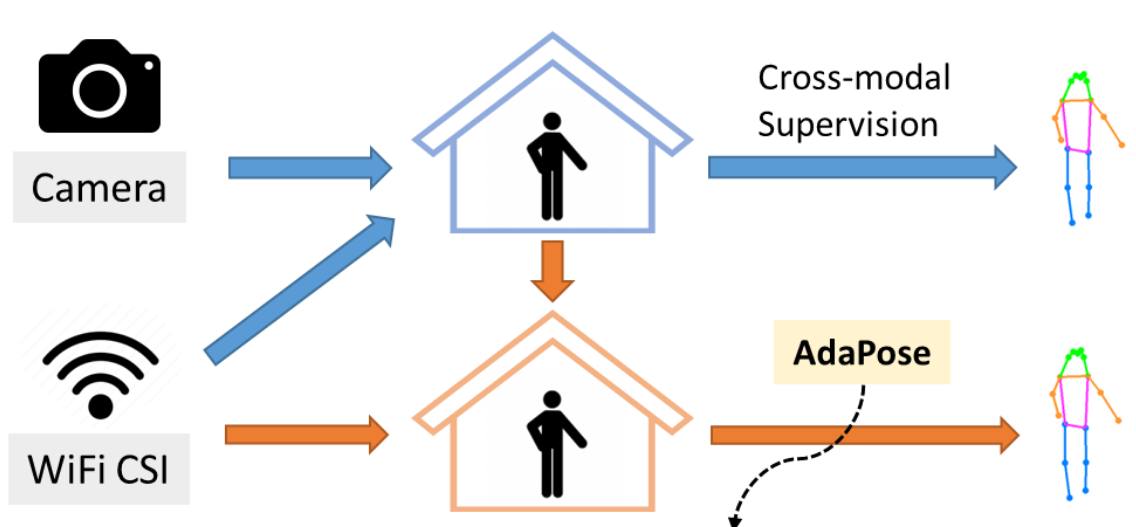
首先在一个确定的环境中进行训练,我们称这个环境为源域(Source domain)。训练的流程大致如下:
采集源域中的WiFi CSI数据,并使用同步摄像头拍摄视频。利用视觉姿态估计模型(如HRNet)处理视频帧,自动生成精确的2D人体骨骼关键点坐标(17个关节点),作为CSI数据的”伪标签”,从而得到带标签的CSI-姿态对样本。
得到用于训练的样本后,首先训练一个端到端的WiFi姿态估计基线模型(如WPNet),该模型包含特征提取器(E)和回归器(R)。特征提取器将CSI数据映射到一个高维特征空间,回归器则将该特征映射为最终的17x2姿态坐标。通过计算预测姿态与伪标签之间的均方误差(MSE)损失,反向传播优化模型参数,使源域中任意CSI输入都能通过该模型准确预测出对应的人体姿态。
在源域中能够进行高精度姿态估计后,下一步就是进行跨场景的泛化,实现步骤如下:
采集目标域中少量带标签(弱监督)或完全无标签(无监督)的姿态对应CSI数据。AdaPose的核心不在于直接对齐源域和目标域的特征分布,而在于对齐它们从”输入(CSI)到输出(姿态)”的映射关系。
通过引入**”映射一致性损失”(Mapping Consistency Loss)来实现这一目标:该损失计算源域和目标域在“输入(CSI)”、”中间特征”和”输出(预测姿态)”三个层级上的分布差异(使用MMD度量),并约束“特征-输入”和“输出-输入”**的差异比率向预设的稳定值收敛。这个过程迫使模型学习一种不受环境动态影响的、内在一致的映射规则,从而在不改变特征尺度的前提下,实现跨域的姿态估计能力迁移。
- 使用最大均值差异(Maximum Mean Discrepancy, MMD) 作为度量工具,分别计算源域(S)和目标域(T)在三个层级上的分布差异:
D_input:源域和目标域输入CSI数据的分布差异。D_feature:源域和目标域中间特征的分布差异。D_output:源域和目标域最终预测姿态的分布差异。
MMD是一种衡量两个分布之间距离的核方法,其值越大,表示两个分布差异越大。
不直接最小化
D_feature或D_output,而是计算它们与D_input的比率:- 特征-输入一致性比率:
R_feat/in = D_feature / D_input - 输出-输入一致性比率:
R_out/in = D_output / D_input